
AI v reklamě: Zkratka k efektivitě nebo slepá ulička pro váš brand?
Píše se rok 2026 a umělá inteligence se stala pevnou součástí našich životů (asi jako předplatné na Spotify nebo chronický nedostatek spánku). V m...
Minule jsme porovnávali klasické SQL a NewSQL databáze z hlediska výkonu a škálovatelnosti. Co když ale potřebujeme něco víc než jen tradiční databázi? Odpovědí je na tuto otázku je ElasticSearch. Pojďme se podívat, proč není jen obyčejnou cache, ale nástrojem, který zvládne i náročné datové operace s minimálním zpožděním.

Pokud jste četli náš první článek, už víte, že pro práci s komplexními daty, např. s produkty, pro jejichž vykreslení potřebujeme celou řadu zdrojů informací, a jejich rychlé zobrazení, lze využít něco, čemu říkáme agregát neboli DTO (Data Transfer Object).
DTO si můžete představit jako jeden velký „balíček“ obsahující všechny potřebné informace o produktu, které se pak nemusí načítat zvlášť z různých částí databáze. Když tento balíček vezmeme a uložíme do mezipaměti, připravíme si rychlou zkratku k informacím, takže načítání produktu probíhá daleko rychleji, než kdyby se každá informace vyhledávala zvlášť.
Agregáty jako DTO jsou skvělou metodou, jak se vyhnout spoustě dotazů do databáze a zpomalovat kvůli tomu načítání stránky. Díky tomuto pomyslnému balíčku je snažší informace o produktu spravovat a zobrazovat uživatelům.
Máme-li všechny potřebné informace o produktu pohromadě ve formě agregátu, je dalším krokem rozhodnout, kam ho uložit, aby byl kdykoliv rychle přístupný. K tomu můžeme využít různé typy cache. A jak už to tak bývá – každá má své výhody i nevýhody.
File cache ukládá data přímo do souborů na serveru. Skvěle se hodí pro uchovávání statických dat (např. šablony nebo obsah), který se moc často nemění (jako u vizuálního rozložení stránek). Tato metoda je levná a jednoduchá na implementaci, ale není úplně nejrychlejší. Pokud potřebujeme pracovat s velkým objemem dat, může přístup k souborům na disku zpomalit načítání.
Oproti tomu APCu cache je rychlá a ukládá data přímo do paměti (RAM) serveru. Tento typ cache je ideální, pokud potřebujeme mít rychlý přístup k menším, často používaným datům – třeba metadatům o stránce nebo uživatelským preferencím. Výhodou APCu je, že vše funguje velmi rychle. Avšak má i vady na kráse, totiž funkčnosti. Jakmile restartujeme server, všechna data z paměti zmizí. Navíc není vhodná na uchovávání větších souborů nebo komplexnějších struktur.
Pokročilá cache, která se hodí pro složitější případy. Potřebujete data nejen uložit, ale také s nimi pracovat (např. opakovaně načítat strukturovaná data nebo provádět rychlé vyhledávání)? Redis je skvělá volba! Dokáže zvládnout i větší množství dat a nabízí funkci trvalého ukládání (perzistence), což znamená, že data nezmizí ani po restartu serveru. Díky tomu se skvěle hodí pro práci s většími kolekcemi dat. Třeba pro uchování výsledků z Doctrine, kterou používáme v PHP pro práci s databází.
Když je naším cílem nejen uložit agregát, ale také s ním dále pracovat, začínají mít tradiční cache své limity. ElasticSearch, původně vyvinutý jako vyhledávací engine, umožňuje nejen data uložit, ale zároveň je bleskově filtrovat a vyhledávat v nich.
Zvládá jak ukládání strukturovaných i nestrukturovaných dat, tak jejich rychlé zpracování bez zatížení konvenční databáze. Díky tomu můžeme data nejen efektivně načítat, ale také snadno filtrovat podle různých kritérií, což nám tradiční cache v takovém rozsahu neumožňují.
Vypadá to, že Redis a ElasticSearch z toho vychází nastejno, že? Jaká je výhoda v použití ElasticSearch, když Redis patří mezi rozšířenější nástroje? Nebojte se ničeho, všechno vám prozradíme.
Redis ukládá všechna data přímo v paměti, čímž zajišťuje mimořádnou rychlost. Když se však paměť zaplní, začne automaticky mazat starší data podle zvoleného algoritmu. A to může být kámen úrazu, pokud potřebujeme data uchovávat trvale.
ElasticSearch na to jde jinak. Data ukládá jako dokumenty na disk a funguje tak „beze ztrát“, protože nehrozí, že by při zaplnění paměti došlo k jejich smazání. Používáme ho, když je zásadní, aby data zůstala kompletní, i když jejich objem roste.
Minule jsme porovnávali výkon klasických SQL databází a novějších NewSQL systémů. Teď jsme proti sobě postavili opět PostgreSQL jako zástupce klasických SQL databází a ElasticSearch, který si do tohoto souboje přináší velkou výhodu – rychlost přístupu k datům i při vysokém zatížení. Abychom toto srovnání provedli v reálných podmínkách, testovali jsme načítání agregátů s několika úrovněmi zatížení.
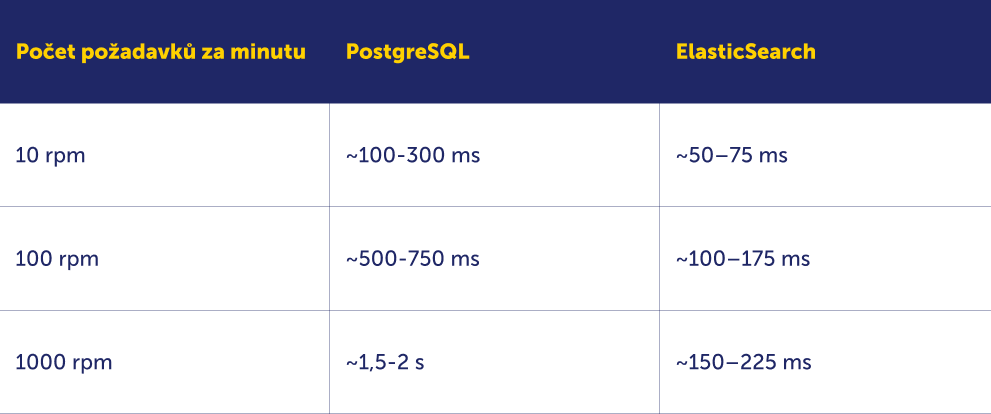

V porovnání s PostgreSQL vykazuje ElasticSearch výrazně nižší odezvu při všech úrovních zatížení, což z něj činí skvělou volbu pro aplikace, které potřebují rychlý přístup k datům. Zatímco PostgreSQL začne při vyšších požadavcích ztrácet na rychlosti, ElasticSearch udržuje nízkou odezvu i při výrazně vyšším zatížení. Jak je to možné? Jednoduše proto, že pouze prezentuje již sestavená data neboli agregáty.
ElasticSearch je prostě postaven tak, aby zvládal horizontální škálování i při intenzivním zatížení, a dokázal rychle zpracovat složité dotazy bez zátěže na konvenční databázi. Díky tomu se stal populární volbou pro aplikace, které potřebují nejen rychlou cache, ale také pokročilé vyhledávací a filtrační možnosti.
TTFB, tedy čas, než uživatel dostane první bajt odpovědi, je klíčovým faktorem rychlosti webu. ElasticSearch pomáhá výrazně snížit TTFB, protože eliminuje potřebu načítat data z několika různých tabulek. Všechny potřebné informace jsou již součástí předem vytvořeného „balíčku“ agregátu, takže první odpověď může být bleskově rychlá.
Díky svému výkonu a rychlému přístupu k datům se stal klíčovým nástrojem pro aplikace, kde je nízký TTFB zásadní – tedy pro e-shopy, rozsáhlé weby nebo aplikace s vysokou návštěvností. Funguje tady totiž nepřímá úměrnost – čím nižší TTFB, tím spokojenější uživatelé. To prostě chcete. A taky je to jeden z hlavních cílů optimalizace výkonnosti.
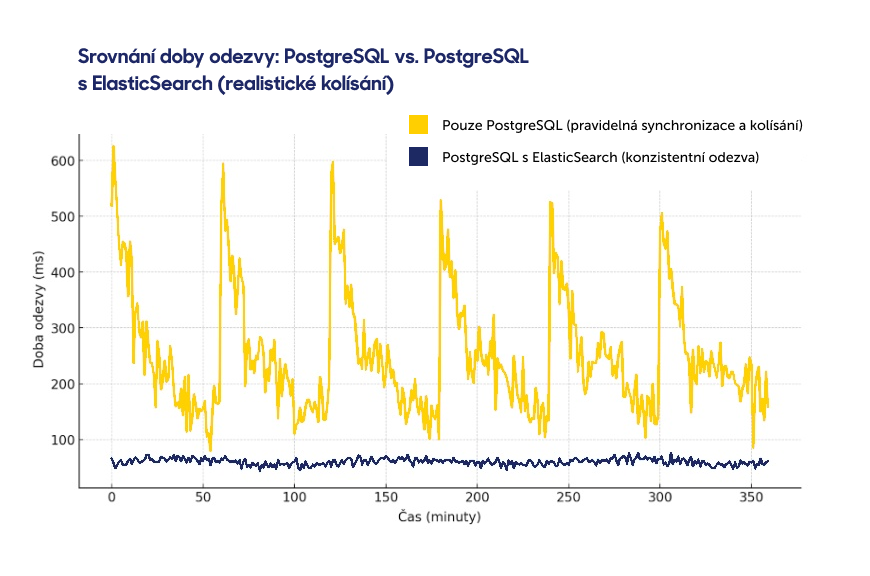
Pokud se zaměříme na TTFB, je důležitá nejen rychlost odezvy serveru, ale i její stabilita. Graf simuluje běh serveru s pravidelnými aktualizacemi článků. U PostgreSQL dochází během synchronizace k zamykání tabulek, což způsobuje zvýšení doby odezvy. Právě při těchto synchronizacích odezva výrazně kolísá, a ani běžný provoz není zcela konzistentní kvůli čtecím a zapisovacím operacím.
Naproti tomu ElasticSearch poskytuje daleko stabilnější dobu odezvy. Prezentuje totiž již předem sestavená a agregovaná data, která nemusí databáze připravovat za běhu. Drobné kolísání v odezvě způsobuje hlavně PHP aplikace, která data zpracovává, a občasné dotazy do databáze např. pro informace o přihlášeném uživateli. Synchronizace dat na pozadí do ElasticSearch se na grafu neprojevuje, protože databáze, do které zapisujeme, neslouží přímo ke čtení, a tedy nezpomaluje odezvu pro uživatele.
Pokud hledáte efektivní způsob, jak optimalizovat výkon vašeho webu, aplikace nebo e-shopu, rádi vám pomůžeme. V Cognito se specializujeme na vývoj webů, aplikací a e-shopů a na vše profesionálně dohlížíme, abyste se mohli soustředit na růst vašeho byznysu. Obraťte se na nás a společně najdeme to nejlepší řešení!
Píše se rok 2026 a umělá inteligence se stala pevnou součástí našich životů (asi jako předplatné na Spotify nebo chronický nedostatek spánku). V m...
Brněnská digitální agentura Cognito.cz spustila nový web Městského divadla Brno, nejoblíbenějšího moravského divadla. Zakázku agentura získala ve ...
Evropský plán na AI gigafactory vypadá na první pohled velkolepě a tak není divu, že jsou ho plné noviny i sociální sítě. Brusel mluví o infrastru...

